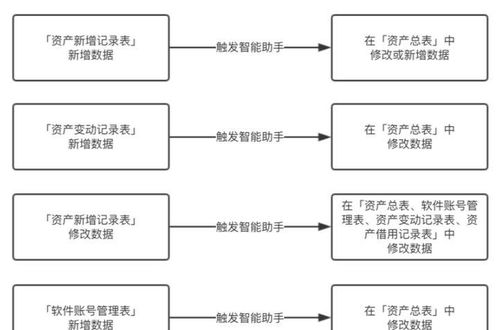
在数据驱动决策的时代,海量、多样、高速的数据既是企业的核心资产,也带来了前所未有的治理挑战。传统集中式、高度依赖IT团队的数据治理模式,已难以满足业务部门对数据即时性、灵活性和易用性的迫切需求。因此,以自动化为核心的自服务大数据治理,正成为企业释放数据价值、赋能业务创新的关键路径。其核心目标是通过自动化工具与平台,将数据处理、质量管控、安全合规等治理能力“服务化”与“民主化”,使业务用户能够高效、自主地完成数据探索、加工与分析,同时确保治理规则的无缝嵌入与执行。
自服务大数据治理的本质,是将治理的“硬约束”转化为易于使用的“软服务”。这依赖于一个由自动化技术支撑的、分层解耦的体系架构。底层是统一的、经过治理的“可信数据源”或数据湖/仓,存储着符合质量标准、定义清晰、安全分级的基础数据。其上构建的是自动化数据处理服务平台,它集成了数据发现与编目、自动化数据清洗与转换、数据质量监控与修复、数据血缘追踪、敏感数据识别与脱敏等核心治理功能。通过可视化、拖拽式的操作界面和自然语言查询等交互方式,业务用户无需编写复杂代码,即可按需申请数据访问权限、组合数据要素、运行数据处理流水线,并实时监控任务状态与数据质量。自动化引擎在后台负责调度计算资源、执行治理策略、记录操作日志,确保每一步操作都合规、可追溯。
自动化是实现高效自服务治理的“引擎”。具体体现在:
- 数据发现与接入自动化:利用元数据自动扫描、分类和打标技术,快速构建企业数据资产目录,智能推荐相关数据集,简化数据查找与理解过程。
- 数据处理流水线自动化:通过预置模板、工作流编排和调度工具,用户可以图形化设计从数据抽取、清洗、转换到加载(ETL/ELT)的全流程,系统自动生成代码并执行,降低技术门槛。
- 数据质量管控自动化:定义数据质量规则(如完整性、一致性、准确性规则)后,系统可自动对流入或处理中的数据进行实时或批次检测,发现问题时自动触发告警甚至执行预定义的修复脚本,形成闭环管理。
- 数据安全与合规自动化:集成数据分类分级策略,自动识别敏感信息(如PII),并依据用户角色和上下文动态实施脱敏、加密或访问控制,审计日志自动生成,满足合规审计要求。
- 血缘分析与影响自动化:自动捕获并可视化数据从源到端的全链路血缘关系,当上游数据或规则变更时,能自动分析并预警对下游数据产品的影响范围,辅助决策。
构建这样的自服务数据处理服务,需要技术与管理的协同:技术上,需融合大数据平台、数据编织(Data Fabric)、机器学习(用于智能推荐与异常检测)和低代码/无代码技术;管理上,需建立配套的数据治理组织(如数据治理委员会)、清晰的权责体系(如数据所有者、数据管家)、面向业务用户的培训与支持机制,以及持续优化的治理策略。
其带来的价值是显著的:一方面,它极大提升了数据获取与分析的效率,缩短了从数据到洞察的时间,加速了业务创新与响应速度;另一方面,它将治理活动从“事后检查”变为“事中嵌入”,通过自动化保障了治理规则的普遍遵守,提升了整体数据质量与安全水平,最终构建起一个既敏捷又受控的数据生态系统,让数据真正成为人人可用、人人敢用、人人善用的可靠资源。