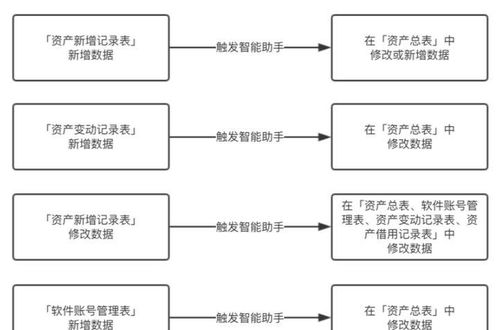
在当今快速迭代的互联网服务中,微服务架构已成为支撑大规模、高并发应用的主流选择。网易云音乐作为国内领先的音乐流媒体平台,其复杂的业务逻辑与庞大的用户基数对系统的稳定性、可观测性提出了极高要求。本文将深入探讨网易云音乐如何基于 Prometheus 构建一套高效、可靠的微服务监控体系,并分享其在监控广告设计(此处指监控体系的设计与规划,而非商业广告)层面的核心实践。
一、 监控体系建设的核心挑战与目标
网易云音乐的微服务架构包含数百个服务,横跨用户中心、音乐推荐、社交互动、广告投放等多个核心模块。在此背景下,传统的监控手段难以满足需求,主要面临以下挑战:
- 海量指标采集:服务实例动态扩缩容,指标数据呈爆炸式增长。
- 多维度关联分析:需要将基础设施监控、应用性能监控(APM)、业务指标监控进行联动。
- 实时告警与快速定位:出现故障时,需快速定位到具体服务、实例乃至代码行。
- 成本与效率的平衡:在保证监控覆盖度的控制存储与计算成本。
为此,团队设定了明确的监控目标:实现从基础设施到应用逻辑的全栈可观测,构建事前预警、事中定位、事后分析的闭环能力。
二、 基于 Prometheus 的监控架构“广告设计”
这里的“广告设计”意指对监控体系本身进行精心“包装”与“推销”,使其在组织内被高效采纳和使用,其核心是设计一套用户(开发、运维、SRE)友好、价值导向的监控方案。
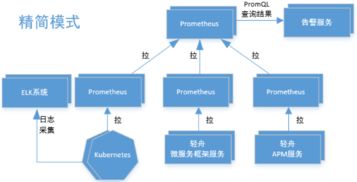
1. 分层采集架构设计
数据采集层:
所有微服务集成 Prometheus Client(如 Java 的 Micrometer),暴露标准化的 metrics 端点。
- 使用
Prometheus Operator在 Kubernetes 集群中自动化管理抓取任务(ServiceMonitor),实现服务的自动发现与监控。
- 对于非 HTTP 服务或中间件(如 MySQL、Redis、Kafka),采用对应的 Exporter 进行指标转换与暴露。
- 存储与计算层:
- 核心采用 Prometheus Server 集群分片部署,按业务域(如用户域、内容域)进行数据分片,降低单点压力。
- 长期存储与历史数据分析迁移至 VictoriaMetrics 或 Thanos,解决 Prometheus 本地存储的限制,实现数据的长期留存与全局查询。
- 告警与可视化层:
- 利用
Alertmanager实现告警的分组、去重、静默及路由,将告警精准推送至钉钉、企业微信、PagerDuty 等平台。
- Grafana 作为统一的监控数据可视化平台,预制涵盖 JVM、HTTP 接口、数据库、业务黄金指标(流量、错误、延迟、饱和度)的仪表盘。
2. 标准化与“产品化”的指标设计(监控的“UI/UX”)
为了让监控数据易于理解和使用,网易云音乐对监控指标进行了“产品化”设计:
- 命名规范:严格遵守
〈namespace〉<em><subsystem></em><metric<em>name>{<label</em>name>=<label_value>}的命名约定,确保指标含义清晰。 - 黄金指标仪表盘:为每个微服务预设四个核心 Grafana 仪表盘:
- 流量:每秒请求数(QPS/RPS)。
- 错误:HTTP 错误码比率、业务异常计数。
- 延迟:请求响应时间分位数(P50, P90, P99)。
- 饱和度:系统资源使用率(CPU、内存)、线程池队列长度、数据库连接池使用率。
- 业务指标埋点:将关键业务动作(如“歌曲播放完成”、“付费成功”)作为自定义指标暴露,实现业务运营与系统性能的关联分析。
3. 智能告警与故障自愈“广告”
有效的告警是监控价值的直接体现。网易云音乐的实践包括:
- 告警分级:根据影响面(全局、局部)和紧急程度(P0-P4)对告警分级,并配置不同的通知渠道与响应流程。
- 避免告警风暴:充分利用 Alertmanager 的抑制规则(Inhibition Rules),当底层基础设施(如节点宕机)告警触发时,抑制由此引发的上层应用级海量告警。
- 告警关联上下文:在告警信息中直接附上相关的 Grafana 仪表盘链接、日志查询链接(如链接至 Loki 或 ELK)以及可能的故障排查 Runbook,极大缩短了平均故障恢复时间(MTTR)。
三、 实践成效与未来展望
通过上述基于 Prometheus 的监控体系实践,网易云音乐获得了显著收益:
- 运维效率提升:新服务上线即具备基础监控能力,故障平均定位时间缩短了 70% 以上。
- 资源成本优化:通过监控数据精准分析服务容量,指导资源弹性伸缩,资源利用率平均提升约 20%。
- 业务保障增强:基于业务指标的监控使技术团队能更主动地感知业务波动,支撑了多次重大促销活动的平稳运行。
团队将继续在监控领域深化探索:
- 向 OpenTelemetry 标准演进:逐步统一 traces, metrics, logs 的采集标准,构建真正的全栈可观测性。
- AIOps 赋能:探索基于机器学习的历史指标分析与异常预测,实现更智能的故障预警与根因分析。
- 可观测性即代码:进一步将监控仪表盘、告警规则等通过 GitOps 进行版本化管理,提升变更的安全性与可追溯性。
###
网易云音乐的实践表明,一个成功的微服务监控体系,不仅需要强大的技术选型(如 Prometheus),更需要像设计产品一样,从用户视角出发,进行体系化的“广告设计”——即通过标准化、产品化、智能化的手段,让监控数据易于获取、易于理解、易于行动,最终将其价值无缝融入研发与运维的每一天,成为保障系统稳定与推动业务发展的坚实底座。